こんにちは、まさかめです。
今回はpythonで行う処理の中でも人気の高いスクレイピングについて紹介していきます。

スクレイピングとは
スクレイピングとは、特定のWebサイト等の情報をプログラムを用いて抽出することです。
例えば、Aというネットショッピング系のサイトをスクレイピングし、各商品の名前と値段を抽出することができたりします。
競合サイトの調査や市場の相場を探ることができるため、昨今のデータを重視したマーケティング等において人気がある状態です。
スクレイピングの流れ
- 調査するサイトを決める
- 調査するサイトをクローリング
- クローリングした内容をスクレイピング
- スクレイピングした内容を保存
調査するサイトを決める
まずはどのサイトを対象にスクレイピングを行っていくかを決める必要がありますが、ここで非常に大切なこととして、対象サイトがスクレイピングを禁止しているかどうかを確認する必要があります。
調査するサイトをクローリング
サイトを決めたらクローリングを行います。
クローリングした内容をスクレイピング
その後、クローリングした内容をスクレイピングしていきます。
スクレイピングした内容を保存
スクレイピングしたデータをそのままにしていても価値に変換できません。
Pythonで引き続き加工するのか、DBに保存していつでも参照できる状態にしておくのか等はありますが、どこかしらに保存しておくことが望ましいでしょう。

容量の大きくないデータならGoogleドライブに保存しておくとかもいいかも!

スクレイピングを行う上での注意点
スクレイピングを行う上で注意するべき点が大きく3点あります。
- 著作権の侵害
- 利用規約の侵害
- 対象サイトへの過剰なアクセス
以下のサイトが詳しく解説しているのでスクレイピングに興味のある方は一度確認しておいた方が良いでしょう。
https://topcourt-law.com/internet_security/scraping-illegal
Pythonでのスクレイピング実装
Pythonでスクレイピングを行うときは以下のライブラリがよく使われます。
- Requests
- Beautiful Soup
- Selenium
- Scrapy
今回はRequestsとBeautiful Soupを組み合わせてヤフーニュースの主要トピックスから、見出しとリンクを抽出していきましょう。

コード
import requests
from bs4 import BeautifulSoup
import re
url = 'https://news.yahoo.co.jp'
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
elems = soup.find_all("a")
elems = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
for elem in elems:
print(elem.contents[0])
print(elem.attrs['href'])
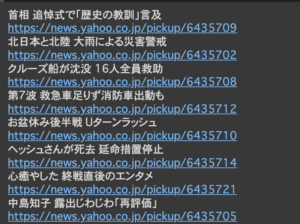
上記プログラムを実行した結果が以下となります。
実際のヤフーニュース上の見出しやリンクと一致しているので問題なくスクレイピングができてそうです。
まとめ
今回はPythonを用いてスクレイピングを実装してみました。
スクレイピングは便利な反面、使い方を誤ると違法となってしまうケースもありますので注意しながら行いましょう。