こんにちは、まさかめです。
今回はXAI(説明可能なAI)を実装するための手段の一つであるSHAPについて解説していきたいと思います。
なお、XAIって何?という方は以下の記事をご参考ください。


XAIとは?
XAIは、”Explainable AI”の略称です。
日本語の意味としては”説明可能なAI”となります。
「AIによる予測結果がなぜそのようになったのかを説明できる」
そういったAIのため”XAI(説明可能なAI)”と呼ばれています。
AIが私達の生活に浸透していく中、以下のような背景がありXAIが注目を集めています。
- AIが発達
- AIの活用が増加
- AIの予測結果に対する不信感が発生
- AIの予測結果への説明を求める声の増加
SHAPとは?
SHAP(SHapley Additive exPlanations)とは、「AIが予測した値に対して、どの特徴量がどれくらい影響を与えたか」を算出するものです。
機械学習を行った際のアルゴリズムにとらわれず、モデルが予測を行った根拠を可視化することができるため、XAIが注目される中でSHAPも注目を集めています。
以下はSHAPの作者によるGitHub上のREADMEファイルからの引用です。
SHAPは機械学習モデルの出力を説明するためのゲーム理論的アプローチであり、昔からあるShapley values (シャープレイ値)を活用したものと記載されています。
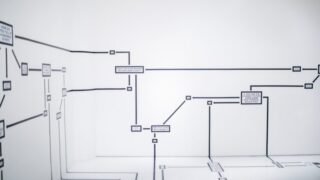
また、画像はSHAPのイメージを表しており、
ブラックボックスである機械学習モデルの中身に対して、どの特徴量がどれだけ出力に関わっているかを表したものとなっています。

SHAP (SHapley Additive exPlanations) is a game theoretic approach to explain the output of any machine learning model. It connects optimal credit allocation with local explanations using the classic Shapley values from game theory and their related extensions (see papers for details and citations).


SHAP実装
ここからは実際にSHAPを用いて「AIの予測結果の説明」を行っていきます。
題材
今回の題材はKaggleの中でも非常に有名な「Titanic : Machine Learning from Disaster」を使用していきます。
▼使用特徴量
・Pclass – チケットクラス
・Sex – 性別
・Age – 年齢
・SibSp – タイタニックに同乗している兄弟/配偶者の数
・Parch – タイタニックに同乗している親/子供の数
・Fare – 料金
・Embarked – 出港地(タイタニックへ乗りこんだ港)
▼予測対象
・Survived – 生存フラグ(0=死亡、1=生存)
▼不使用
・PassengerId – 乗客ID
・Name – 乗客氏名
・Ticket – チケット番号
・Cabin – 客室番号
LightGBM実装
まずはLightGBMを用いてタイタニック号の生存予測を行います。
#### 事前準備 ####
# ライブラリのインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# データ読み込み
df = pd.read_csv('titanic.csv')
#### 前処理 ####
# 年齢欠損値を中央値で補完
df['Age'] = df['Age'].fillna(df['Age'].median())
# 寄港地がnullのレコードを除外
df = df.dropna(subset=['Embarked'])
# 寄港地ダミー変数化
df['Embarked'].replace('S', 0, inplace=True)
df['Embarked'].replace('C', 1, inplace=True)
df['Embarked'].replace('Q', 2, inplace=True)
# 性別ダミー変数化
df['Sex'].replace('male', 0, inplace=True)
df['Sex'].replace('female', 1, inplace=True)
# データ型の変換
df = df.astype({'Sex': int, 'Embarked': int})
# 使用しないカラムを削除
df = df[['Pclass', 'Sex', 'Age', 'Fare', 'Embarked', 'SibSp', 'Parch', 'Survived']]
# 目的変数・説明変数
x = df[['Pclass', 'Sex', 'Age', 'Fare', 'Embarked', 'SibSp', 'Parch']]
y = df['Survived']
# データ分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42)
#### モデル作成と学習結果 ####
# モデル構築
model = lgb.LGBMClassifier(random_state=42)
# 学習
model.fit(x_train, y_train)
# 予測
y_pred = model.predict(x_test)
# 正解率を算出
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
# 正解率を出力
print('Accuracy: ', round(accuracy*100, 2), '%')
print('Precison: ', round(precision*100, 2), '%')
print('Recall : ', round(recall*100, 2), '%')
print('F1 : ' , round(f1*100, 2), '%')
# 寄与度算出
importance = pd.DataFrame(model.feature_importances_, index=x_test.columns, columns=['importance']).sort_values('importance', ascending=False)
display(importance)SHAP実装
さて、今回のメインであるSHAPの実装です。
まずはSHAPをインポートし、先程作成したモデルを読み込ませていきます。
import shap
# SHAPでJSを使用するためJSを読み込み
shap.initjs()
# 学習済みモデルと学習データから、SHAP値を計算する
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(x_train)
各特徴量のモデルへの貢献度
shap.summary_plot(shap_values, x_train)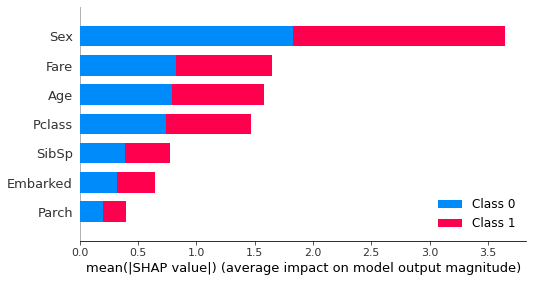
各特徴量のSHAP値への影響
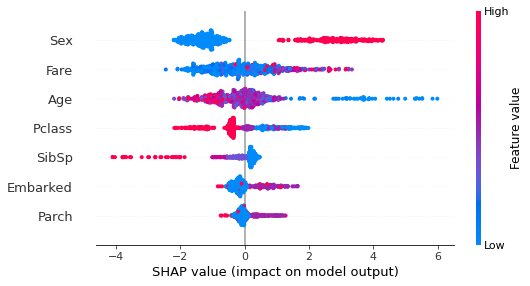
ここから、性別が女性・年齢が若いと生存しやすく、兄弟/配偶者の数が多いほど生存しにくい傾向があることがわかります。
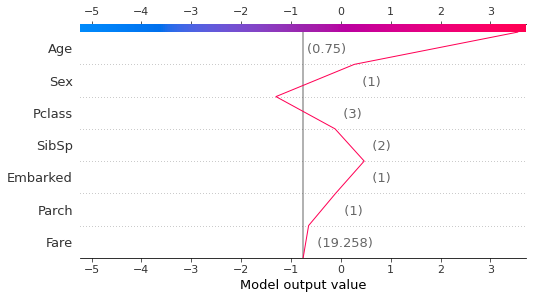
データごとの生存予測に対する特徴量の影響
shap.force_plot(explainer.expected_value ,
shap_values[10, :],
x_train.iloc[10, :]
)
shap.decision_plot(explainer.expected_value,
shap_values[10,:],
x_train.iloc[10, :])
,
shap_values[10, :],
x_train.iloc[10, :]
)
shap.decision_plot(explainer.expected_value,
shap_values[10,:],
x_train.iloc[10, :]) ,
shap_values
,
shap_values
まとめ
今回はXAI(説明可能なAI)を実装するための手段の一つであるSHAPについて解説してきました。
AIによる予測結果が「なぜそう算出されているのか」を説明するために有用な手段なので、ぜひ理解して使ってみてください。